研究概要と研究例
 研究概要および研究方法
研究概要および研究方法
人間・動物はすばらしい情報処理機能を持っているが、まだ解明されていない機能も多い。
その機能の情報処理過程を解明し、人工的な情報処理で壁・困難な問題にぶつかったとき、生体情報処理の方法に学び
打開策を検討し、できれば人間・動物と同等か上回る機能を持つ人工物を作る基礎を築きたい。
主要業績概要:
もう少し詳しい研究成果概要
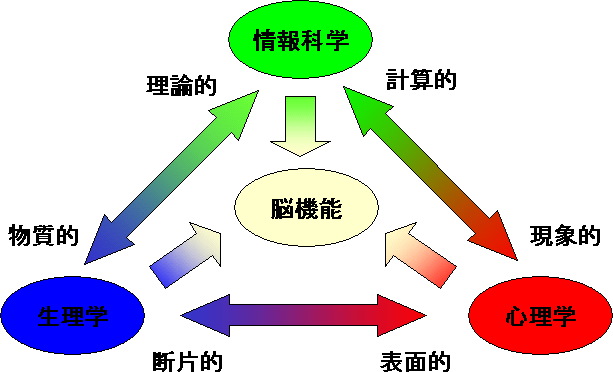
脳研究の大きな柱(下図)において、生理学・心理学的な知見をよく吟味し(時と場合により自ら行なうこともある)情報科学的アプローチをとりながら多視点から研究を進めていく。
 研究例---試行錯誤からの柔軟な学習 ---
研究例---試行錯誤からの柔軟な学習 ---
強化学習の学習パラメータ制御法
人間は試行錯誤の行動をして得られる結果(報酬)から学習を行い最適な行動を取得する強化学習を
行うことができます。そのような強化学習のアルゴリズムが提案されていますが、従来の強化学習は再学
習を行うときに時間がかかるという問題がありました。しかし人間は今までうまくいっていた行動が突然うまくいかなくなったら、他の行動を試行錯誤により模索し、別の良い行動を比較的早く取ることができます。
そこで強化学習アルゴリズムを制御しているパラメータを人間の頭の中で色々な状況の時に放出されて行動制御にも関わって来ると考えられる神経修飾物質とみたてて、うまく制御し柔軟に学習を行うアルゴリズムを提案しています。
ちなみに神経修飾物質とは、脳の働きかたをある程度広い領域で変化しコントロールするような物質で、ドーパミン(多いと快感、少ないと無気力)、セロトニン(多いと楽天的、少ないと衝動的)、ノルアドレナリン(多いと高揚、少ないと落胆)、アセチルコリン(多いと記憶力上昇、少ないと記憶力低下)をここでは想定しています。
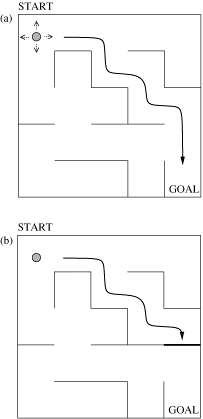
図において、左上のスター
トから右下のゴールまでの道筋を強化学習で学習した後(図a)、途中に新しく壁を設ける(図b)。
従来の強化学習アルゴリズムではなかなか迂回路を探し出すことができないが、提案手法では比較す
ると素早く迂回路を探し出すことができます。
こちらで実行して見ることができます。こちらは自動化されているのでほとんど見ているだけになります。
比較のために従来の方法であるこちらを実行して見ると、そのまま放っておけば随分と時間がかかりますし、手動でうまく変えてやろうとしてもなかなか難しいことがわかります。
手動でコントロールできるのは、γ(ガンマ)がセロトニン、α(アルファ)がアセチルコリン、β(ベータ)がアドレナリンの三つです。
セロトニンだけは増えると対応するパラメータは小さいですが、他は逆です。
アームロボット前進問題はこちらにありますが、トンネルの追加ができていません。ただ、前進するのを学習するだけです。ちなみにアルゴリズムは迷路問題と同じで解くことができます。